Apache Spark: Procesamiento Distribuido

¿Qué es Apache Spark?
Apache Spark es un framework Open Source desarrollado para ofrecer velocidad y gran capacidad de procesamiento en la gestión de grandes volúmenes de datos.Spark está diseñado para la ciencia de datos y su abstracción facilita este tipo de tareas. Los científicos de datos suelen usar algoritmos de machine learning, los cuales se caracterizan por ser repetitivos. La habilidad de Spark para mantener en memoria un conjunto de datos incrementa considerablemente la velocidad de procesamiento, haciendo a Spark el motor ideal para la implementación de este tipo de algoritmos.
Velocidad
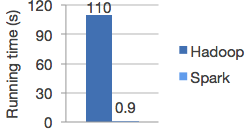
Spark permite a las aplicaciones en clústers Hadoop ejecutarse hasta 100 veces mas rápido en memoria y hasta 10 veces mas rápido cuando se ejecutan en disco. Spark provee de un marco de trabajo fácil de entender y unificado para manejar grandes volúmenes de datos en sus distintas formas (texto, grafos, etc.) como también de distintas fuentes (por lotes o en tiempo real).
Facil de usar
Se pueden programar aplicaciones con Spark en Java, Scala o Python (algunas cosas en R). Provee de un set de mas de 80 operaciones de alto nivel, faciles de entender y utilizar. Y se puede utilizar de forma interactiva a través de la terminal.
Así de fácil es el canónico "Contar Palabras" del paradigma MapReduce a través de Spark en Python:
archivo_texto = sc.textFile("hdfs://...")
archivo_texto.flatMap(lambda linea: linea.split())
.map(lambda palabra: (palabra, 1))
.reduceByKey(lambda a, b: a+b)
archivo_texto.flatMap(lambda linea: linea.split())
.map(lambda palabra: (palabra, 1))
.reduceByKey(lambda a, b: a+b)
Arquitectura
Spark cuenta con librerías como SparkSQL para trabajar sobre DataFrames, MLlib para Machine Learning, GraphX para el procesamiento de grafos, y Spark Streaming para el procesamiento de datos en tiempo real. Todas estas librerías se pueden combinar indiferentemente en una misma aplicación.

¿Donde aprender más?
La documentación de Spark es realmente muy buena, así que ese puede ser un buen lugar para iniciar.
Actualmente se puede encontrar un curso gratuito en edX que permite entender los conceptos básicos de Apache Spark y el procesamiento distribuido.
Referencia:
Hortonwrks. Apache
Spark & Hadoop. http://hortonworks.com/hadoop/spark/
Apache Spark: Procesamiento Distribuido
 Reviewed by Josemy
on
18:48
Rating:
Reviewed by Josemy
on
18:48
Rating:
Reviewed by Josemy
on
18:48
Rating:






.bmp)

No hay comentarios: